
Linear regression with multiple variables
| Coursera machine learning exercise 1 |
Feature Normalization
When features di ffer by orders of magnitude, performing feature scaling can make gradient descent converge much more quickly.
The code in featureNormalize.m is used to
• Subtract the mean value of each feature from the dataset.
• After subtracting the mean, additionally scale (divide) the feature values by their respective "standard deviations".
When features di ffer by orders of magnitude, performing feature scaling can make gradient descent converge much more quickly.
The code in featureNormalize.m is used to
• Subtract the mean value of each feature from the dataset.
• After subtracting the mean, additionally scale (divide) the feature values by their respective "standard deviations".
| featurenormalize.m |
Gradient Descent
The codes in computeCostMulti.m and gradientDescentMulti.m are used to calculate the cost function and gradient descent for linear regression with
multiple variables.
The codes in computeCostMulti.m and gradientDescentMulti.m are used to calculate the cost function and gradient descent for linear regression with
multiple variables.
|
| ||||
Selection of Learning Rate
It is recommended to try values of the learning rate on a log-scale, at multiplicative steps of about 3 times the previous value (i.e., 0.3, 0.1, 0.03, 0.01 and so on).
It is recommended to try values of the learning rate on a log-scale, at multiplicative steps of about 3 times the previous value (i.e., 0.3, 0.1, 0.03, 0.01 and so on).
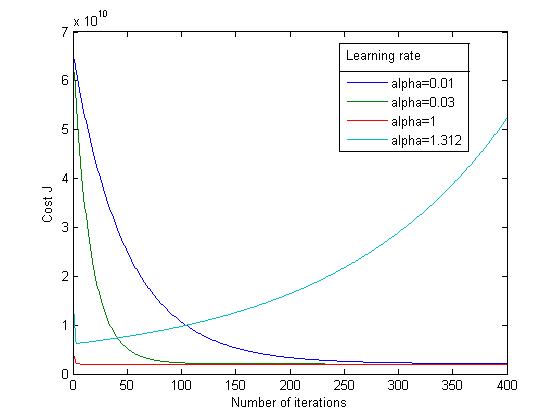
Cost function value history for different learning rates
Normal Equations
Here we use the formula to get the closed-form solution of theta to linear regression directly.
Using this formula does not require any feature scaling, and an exact solution can be achieved in one calculation: there is no "loop until convergence" like in gradient descent.
The disadvantage of this approach is that when the example number is very large, it is costly to solve the inverse of matrix.
Here we use the formula to get the closed-form solution of theta to linear regression directly.
Using this formula does not require any feature scaling, and an exact solution can be achieved in one calculation: there is no "loop until convergence" like in gradient descent.
The disadvantage of this approach is that when the example number is very large, it is costly to solve the inverse of matrix.
| normaleqn.m |
